Impetus
In Autumn 2017, we had an incident involving multiple services crashing and failing to re-initialize. We quickly correlated the time of the crashes with the time our Elastic Stack became unavailable. We then determined that our logging library did not put a maximum capacity on the number of log messages in the publish queue (see gomol issue #20), causing the memory usage of the application to rise when logs could not be pushed out. Eventually, this caused process memory to increase to the point where the OOM Killer kicked in and forcefully stopped the applications. To make matters infinitely worse, our JSON log adapter library required a successful connection to be made on startup before the app could re-initialize (see gomol-json issue #3). Once an application crashed, it could not come back up without someone listening for our precious, precious logs.
Ouch.
We patched these issues in gomol pull request #21 and gomol-json pull request #3 and updated dependencies in the affected applications.
But not all of them.
We happened to find out exactly which services were still using the old version of the library because, as luck would have it, our elastic stack once again became unavailable and the exact same behavior recurred. At least the second time was a quick deploy (as the changes were already made to the required libraries), but customers were … not ecstatic, to say the least.
Overview
This inspired us to write Deposition. Deposition is a self-hosted API which allows services to self-report their dependencies. On each successful automated build of the master branch, we extract the dependencies from the resulting application (generally produced as a docker container) and push them to the API along with the product name, product version, and a unique build token (generally the bamboo build number).
For each type of project (and each type of project package management), we automatically extract the installed dependencies. For Golang projects, we use Glide to lock dependencies to a VCS revision. This allows us to use the glide.lock file checked into the repository. For Python and JavaScript-based projects, we can use pip freeze and npm ls --json, respectively, to read installed versions directly from the package manager. It’s important to note that we do this inside of the container produced as an artifact so we get the true dependencies present in a production environment (and not dependencies installed as part of the build process or dependencies which just happened to be on a developer machine or build agent).
We do the same thing for operating system-level packages. For containers which use Debian as a base, we do the following.
| |
This creates a file that begins with the OS distribution version, then followed by the names of installed packages and their versions. For containers which use Alpine as a base, we do the following.
| |
This is a bit more involved, as apk info gives only installed package names but not versions, and apk info -v gives us a combination of the two (but not in a way which the package name and version are easily separated). The bash pipeline correlates these two sources together, extracts the versions, then writes a file which is more easily (and unambiguously) parsable by the API.
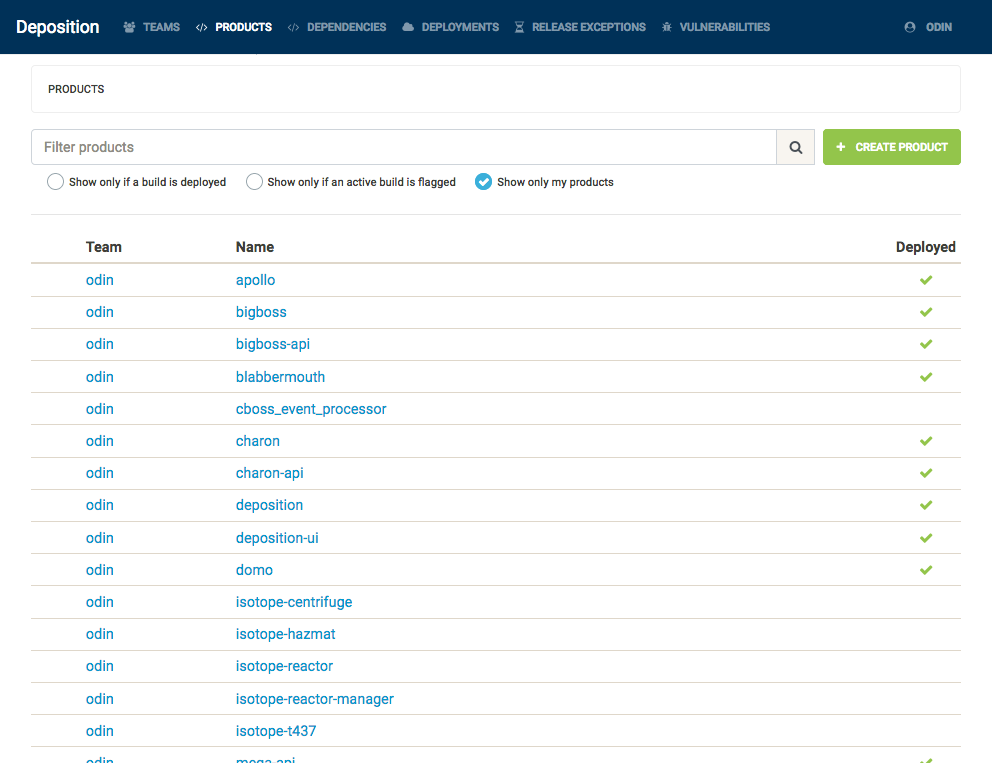
The following screenshot shows the products of which Deposition is aware. This list only contains services which are currently self-reporting – we are still in the process of moving older services to use our new build conventions.
On the other side of the build pipeline, on each successful deploy, we inform the API that a particular build has made it into a production environment with some unique build token (these could be a marathon path, a server name and binary path, or a Fargate task identifier, or a simple string which is meaningful to your development process).
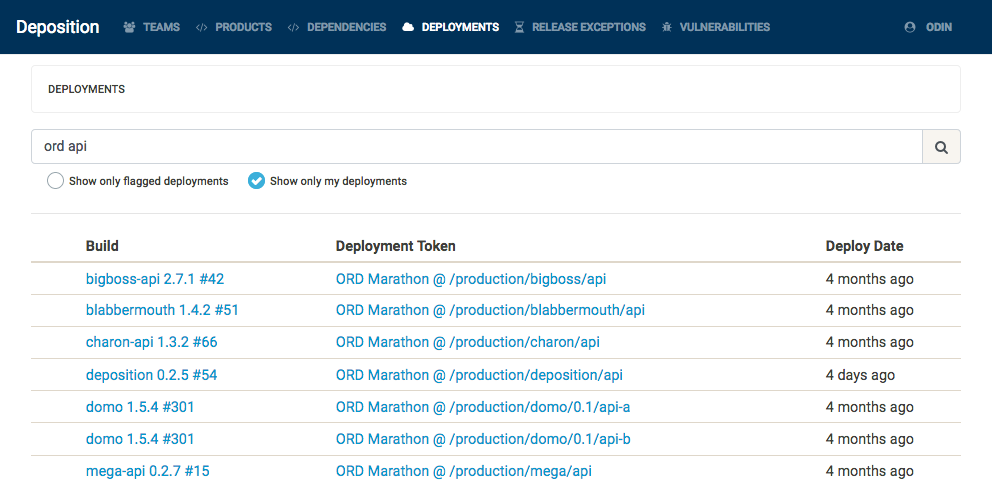
The following screenshot shows all active deployments of a service whose name contains the word api in our Chicago data center. At a glance, we can see exactly which version and which bamboo build created the production artifact (without scraping several APIs and correlating the docker tag of the Marathon task with Bamboo build logs).
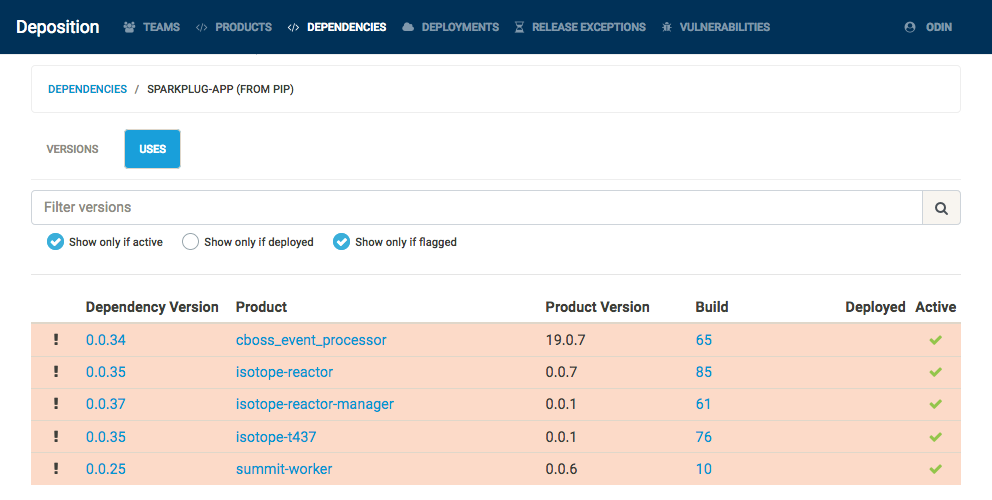
This allows us to retrieve an always-current list of deployed builds and the active (either deployed or most recent) builds of a product. This also allows us to query, in both directions, the relationship between builds and dependencies. In one direction, we can see all the dependencies of a build (or all aggregate dependencies of a product). In the other direction, we can see all the builds which depend on a particular dependency version (or all aggregate versions of a dependency).
Instant Deprecation
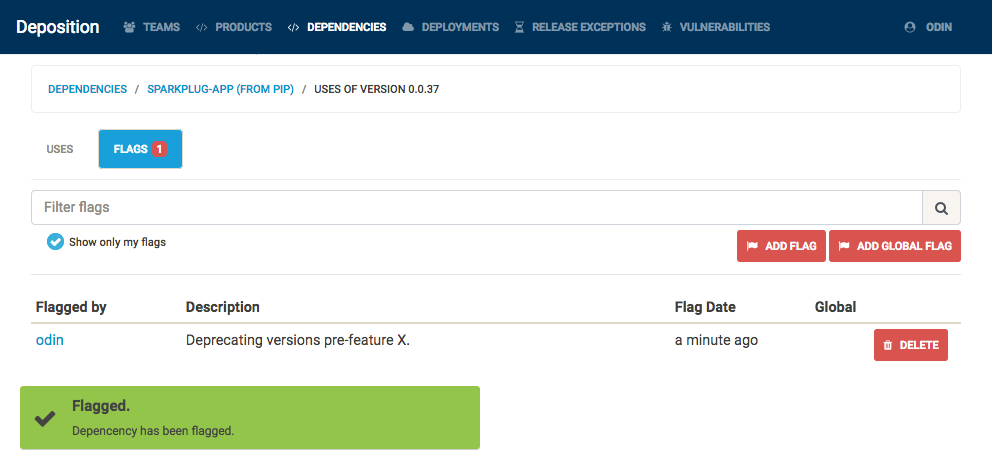
How would this have changed our double-outage example above? Once we determine that there exists a bug, vulnerability, or other reason to deprecate, we can simply flag a particular dependency version with the reason. A dependency flag created by a team does not necessarily apply for another team – however, there are certain roles (security teams and automated CVE list scanners) which can apply a dependency flag for all teams.
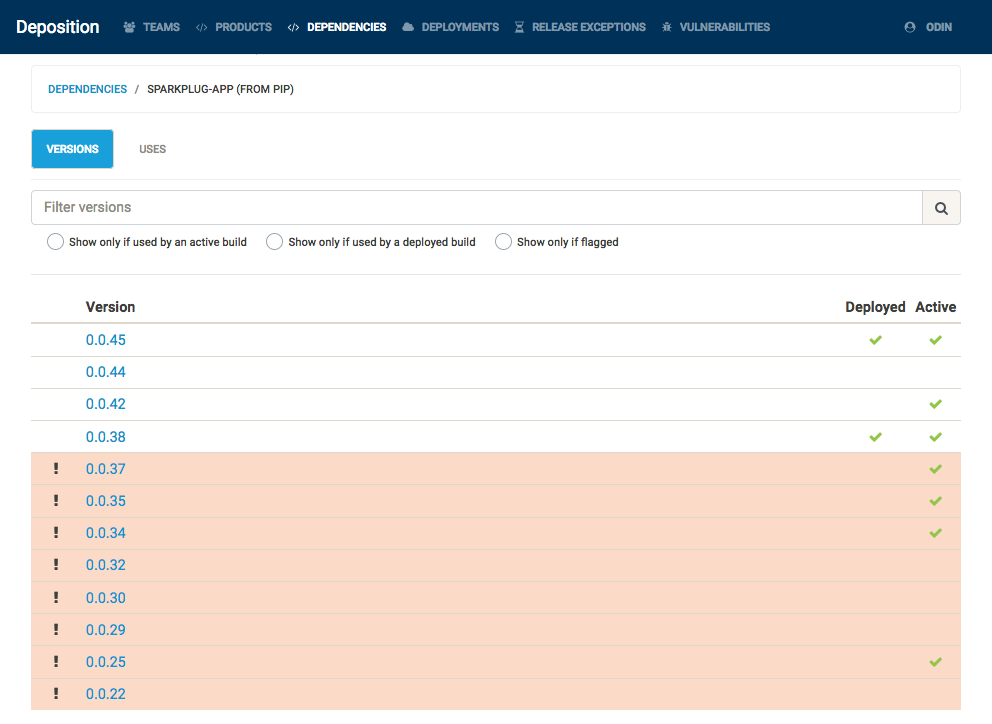
Also, as Deposition understands the how to compare two versions for particular sources, flagging a dependency at a particular version will also apply that flag to all lower versions of that dependency, as shown below. At present, Deposition understands the semantics of Alpine package versions, Debian package versions, and semantic versions used by pip and npm.
When a dependency version is flagged, all builds using that version are flagged, any deployment using a flagged build is flagged, and any product with an active flagged build is flagged. Depending on the team configuration, a JIRA ticket or a GitHub issue is created for all deployments and active builds which were newly flagged by this action. This gives teams something automated to act on instead of having to search for what to replace via the Deposition UI.
This also changes the process for future actions: any new build which uses a flagged version is rejected by the Deposition API and the automated build fails, and any new deployment which refers to a flagged build is similarly rejected. This makes it impossibly to accidentally build and deploy a service with vulnerable dependencies (although Deposition does provide an escape hatch to allow such builds through when absolutely necessary).