Resume
Work History
 Atlassian
Atlassian
Coming soon!
 Render
Render
Render is building a powerful, easy-to-use cloud platform to host anything online, from simple static sites to complex applications with dozens of microservices. I’m an engineer on the Datastores team, which delivers managed Postgres and Redis databases. The Datastores team was focused on building powerful, flexible tools that scale with our customers’ needs with little effort from them. Render’s Datastore products provide our customers optimization insights and advanced workflows when it becomes appropriate for them, without having to hire a DBA or operations team.
My impact on the Datastores team includes:
Dynamic configuration: I introduced a system to apply Postgres configuration dynamically and individually to each user database instance. Previously, all configurations were static, regardless of plan size or usage patterns. Dynamic configuration allows the Postgres process to use the available CPU, memory, and disk resources more intelligently, enabling applications to utilize the instance more fully. Dynamic configuration also provides a foundation for Render employees to set instance-specific specific configuration. Additionally, the Render platform can automatically change configuration based on instance-specific usage.
Alert automation: We strive to completely eliminate alert conditions at their source, but it isn’t always possible to ascribe a single solution over a fleet of databases with heterogeneous scale and workloads. Individual databases will sometimes enter conditions that need to be handled reactively (e.g., a user filling up their instance’s disk or a WAL segment being dropped prior to replication under heavy and spiking load). To reduce engineering burden, I created a system that automatically responds to alerts triggered in our observability stack. This system leverages dynamic configuration where possible to reduce the occurrence of the same condition for a particular instance.
Continuous testing: Developing managed databases is a tricky business. While Render utilizes unit, integration, and end-to-end tests, it’s impossible to exercise the full surface area of features within a CI pipeline. I created Pulsegres, a continuous testing framework, that maintains a set of long-lived Postgres instances with non-trivial scale. This system detects behavior-altering code changes that would not be identified using fresh, small end-to-end testing instances, and has reproduced odd behavior with our High-Availability offering before it affected customers on several occasions.
Service links: I led collaboration with product and design teams to develop and roadmap the Service Links project. Previously, users of Render would have to locate connection strings for the databases and manually add environment variables in their web service or cron jobs to connect them. This relationship is effectively outside of Render’s view. Service links enable seamless, direct connection between compute and database resources on the Render platform. The Render platform now has greater observability about what apps connect to what database, a better view of a user’s application topology, and gives a foundation for later finer-grained authorization and access controls.
Heroku migrations: Migrated several high-ARR customers from Heroku to Render, and automated the process to be repeatable with future migrations. The process involved a low-downtime switchover period that minimized the disruption to the customer’s application, and opaquely handled a necessary reindexing step that occurs with locale mismatch (as Heroku and Render used different base operating systems). Without reindexing, queries involving an index with a stale locale may fail to retrieve data, which appears as data loss to the user. Reindexing was done intelligently, affecting the minimum number of indexes, and performed as much work as possible in parallel to minimize the time in which the indexes were invalid.
Cost optimization: Saved an estimated $480k in 2024 by optimizing Postgres backups by reducing cross-region data transfer and automating the periodic removal of backup data that was no longer necessary to retain.
 Sourcegraph
Sourcegraph
I was a staff-level software engineer leading the Language Platform Team (a subteam of Code Intelligence). Our team worked to provide fast and precise code intelligence to power code navigation operations such as cross-repository go-to-definition and global find-references. Most recently, we were expanding our scope to usefully provide precise code intelligence data to other product teams at Sourcegraph.
My goals for the platform revolved around increasing adoption of precise code intelligence by supporting an increasing number of languages, build systems, and project configurations in our auto-indexing infrastructure; and pivoting the current persistence and API structure from LSIF to SCIP, a code intelligence index format that we developed in early 2022 that unlocks the next generation of code intelligence features.
I have on occasion ventured from my home team to solve impactful or urgent problems.
Executors are an instance-external component which are tasked with running user-supplied (and possibly arbitrary) code safely in a sandbox. Executors were designed with a strong emphasis on security for both multi-tenant our SaaS offering as well as our single-tenant self-hosted offering, and achieves multi-tenant isolation via Fircracker MicroVMs. Executors now power auto-indexing as well as our server-side code modification offering, both of which rely on the ability to execute user-supplied and possibly untrusted code.
Database migrations were a mess! Developers adding new migrations would frequently conflict with concurrent activity (often subsequently breaking the
mainbranch). Upgrades and rolling restarts would frequently require manual intervention from the instance’s site-administrator, burdening end-users in our self-hosted environments and burdening on-call engineers with trivial issues for oru SaaS offering. To solve this, I designed a migrator component that would validate and apply database migrations prior to application startup (opposed to during). This separation allowed us to more easily extend and harden application of schema migrations. See the introductory blog post for further technical details. In a similar spirit, I designed a system to apply out-of-band migrations, which run in the background of the instance over time. This is useful when migrating large amounts of data, or requiring Postgres-external behaviors as part of the migration process (e.g., encryption routines).Multi-version upgrades were unsupported until September 2022. Historically, Sourcegraph instances can only be upgrade a single minor version. As upgrades are a fairly hands-on process, the majority of our self-hosted instances were two or more versions behind our latest release (some instances running versions as old as two years). I continued my work on database migrations to extend the migrator utility so that it could skip forwards and backwards to any tagged release, allowing both upgrades through multiple versions, as well as downgrades. See the blog post for additional design details as well as a multitude of hurdles I encountered while fleshing out the nitty-gritty.
PageRank, the algorithm behind determining relevance of Google’s search results, was utilized to inform our own search results ordering. I implemented a proof-of-concept data pipeline that exports a large graph encoding a global set of source code text documents (over all repositories for which we have precise indexes) and symbol relationships between them (e.g., file A refers to a symbol in file B). This graph is ready by Spark executors in our cloud environment, outputting global PageRank scores for each document, which can subsequently be used to inform the order which we pack our trigram index shards. This allows our search backend to return highly relevant results first, without requiring a subsequent sorting step once relevant documents have been fetched. Sourcegraph’s Head of Engineering, Steve Yegge, blogged about the future this indicates for the product. See the technical deep-dive blog post for specifics on this data pipeline and how we chose to construct such a document graph.
 Mitel
Mitel
I was a senior software engineer on the Labs team focused on building proof of concept solutions for new investment areas. Most recently, I was focused on building Nighthawk, an IFTTT-like engine to orchestrate communication of relevant parties during incident responses. Users could define their own workflows and integrate with a ecosystem that hosts third-party behavioral extensions. Before that, I was focused on Mitel’s Internet of Things Collaboration strategy, Kestrel, which involved building out infrastructure for registering LoRa gateways and devices and reading, storing, and aggregating sensor readings.
Prior to the formation of the Labs team, I was on the team platform building Summit as part of Mitel’s Unified Communications Platform as a Service offering. This allowed customers to build voice and SMS applications as Lua code that would run in a containerized sandbox.
I was the primary author the following infrastructure and developer experience projects, primarily written in Go and Python with a bit of C (via Redis modules).
Apollo is an audio streaming server which mixes hold music and announcements from tenant-configurable playlists. The server self-regulates load by redirecting attached clients to servers which are already serving a particular audio file, minimizing the bytes in-flight from the audio storage system.
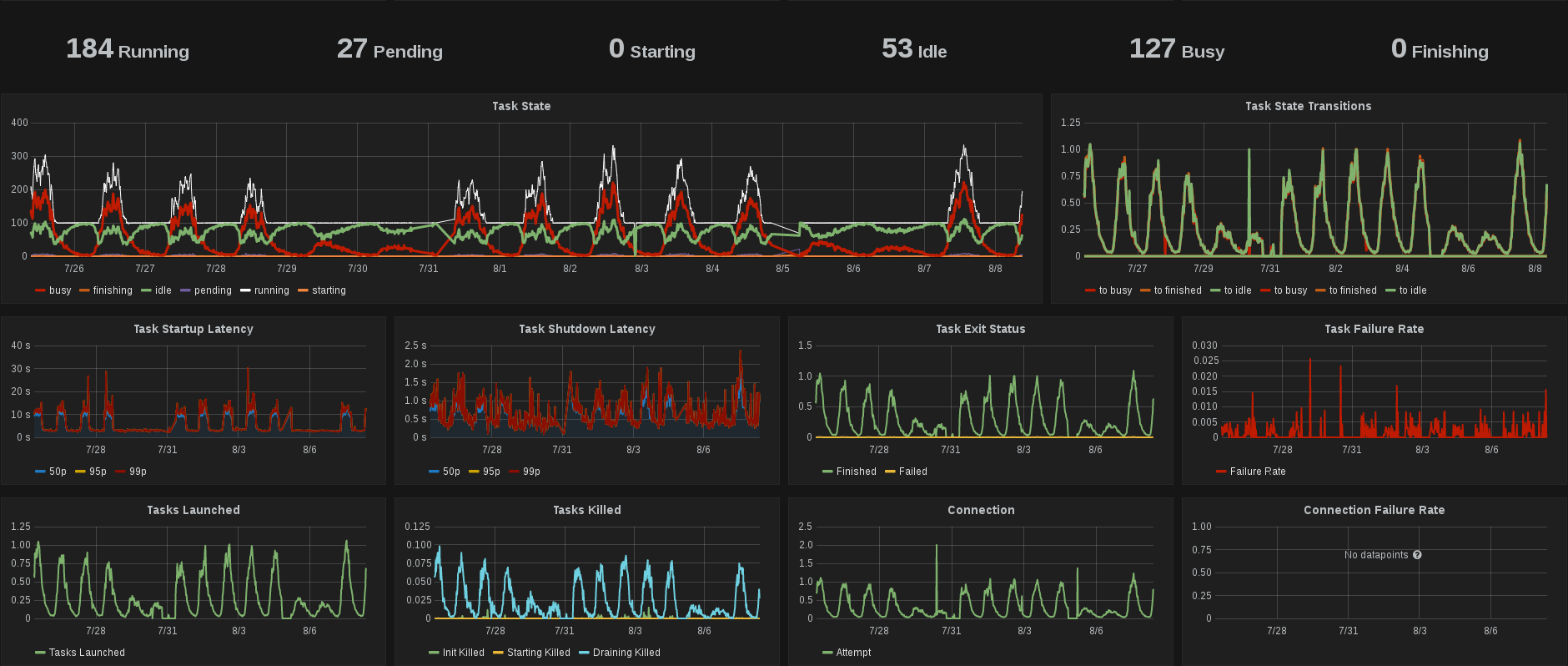
Bigboss is a Mesos framework and deployment system for frequent-churn containers. Bigboss elastically schedules call processor services so that at any given time between 30-40% of all running processes are available to accept a new call without delay. When new call processor code is deployed, idle call processors are shut down and replaced with a fresh container running the updated version. The following image is a portion of the scheduler metrics dashboard over the course of two weeks (for one datacenter). Peaks indicate heavy call traffic, and the two-day flat line periods are the weekend, where call volume does not generally exceed our elastic scaling threshold.
Charon is a distributed limiting service which grants or denies an internal application permission to use a resource on behalf of a tenant based on current resource usage and the tenant’s recent usage history. The service increases infrastructure reliability by ensuring that no resource is overcommitted, and ensures that no single tenant can utilize a disproportionate amount of resources with respect to a tenant’s service-level agreement. Technical details are available in the Whitepaper, and an interactive example is available in the request simulator.
Deposition is an internal tool used to track software lifecycle metadata such as builds, dependencies (including vulnerabilities), and deployments of our internal infrastructure. See the blog post for the original motivation and additional product and implementation details.
- Domo is an S3-aware HTTP proxy layer in front of Ceph Object Store which allows for automatic, instantaneous failover to a remote data center when the local Ceph cluster is slow or unresponsive. The server synchronizes clusters across data centers on write requests so that a write to any data center will (eventually) become globally consistent.
ESDN, Inc.
Developed an e-commerce and supply chain web application which streamline interactions between jewelry consumers, retailers, and suppliers. Major projects include a consumer-facing jewelry collection showcase and a retail (brick-and-mortar) location management system. Primary technologies include ASP.NET MVC using C# and MSSQL.
Education
Ph.D. Computer Science
My dissertation, Waddle - Always-Canonical Intermediate Representation, was supervised by John Boyland.
Abstract: Program transformations that are able to rely on the presence of canonical properties of the program undergoing optimization can be written to be more robust and efficient than an equivalent but generalized transformation that also handles non-canonical programs. If a canonical property is required but broken earlier in an earlier transformation, it must be rebuilt (often from scratch). This additional work can be a dominating factor in compilation time when many transformations are applied over large programs. This dissertation introduces a methodology for constructing program transformations so that the program remains in an always-canonical form as the program is mutated, making only local changes to restore broken properties.
MS Computer Science
My thesis, Optimizing the RedPrairie Distance Cache, was supervised by Christine Cheng.
Abstract: RedPrairie’s Transportation Management products are based on a suite of optimizers that approximate solutions for the Vehicle Routing Problem, a well-known NP-hard problem. The optimizers work by heuristically updating portions of route assignments and require many prohibitively expensive queries to a Geographic Information System. The thesis explores several strategies for caching queries in-memory – specifically, how can hash tables be organized to maximize the entries which can fit in resident memory, and which cache eviction strategies retain the most useful data with respect to the optimizer’s access patterns.
RedPrairie was acquired by JDA Software Group, Inc in 2012.
BFA Film
I received a Bachelor of Fine Arts in undergrad studying film theory and production.
Teaching History
University of Wisconsin – Milwaukee
- CompSci 658 / 790 – iOS Programming
- CompSci 482 – Server-side Internet Programming
- CompSci 481 – Rich Internet Applications
- CompSci 655 – Compiler Implementation Laboratory
- CompSci 251 – Intermediate Computer Programming
- CompSci 744 – Text Retrieval and Its Applications in Biomedicine
- CompSci 395 – Social, Professional, Ethical Issues
- CompSci 361 – Introduction to Software Engineering
- CompSci 351 – Data Structures and Algorithms
- CompSci 315 – Assembly Language Programming
- CompSci 201 – Introduction to Computer Programming
- CompSci 150 – Survey of Computer Science